In the August 25th Economist, a piece “NEON Light: A 30-year plan to study America’s ecology is about to begin”. Highlights from Boulder CO:
… a group of American ecologists, led by David Schimel, … plan to shake up terrestrial ecology, and introduce it to the scale and sweep of Big Science, by establishing NEON, the National Ecological Observatory Network.
… NEON’s researchers have divided America into 20 domains …, each of which is dominated by a particular type of ecosystem. Each domain will have three sets of sensors within it. One set will be based in a core site — a place where conditions are undisturbed and likely to remain so — that will be monitored for at least 30 years. The other two sets will move around, staying in one place for three to five years before being transplanted elsewhere. These “relocatable” sites will allow comparisons to be made within a domain.
Here’s the map of ecosystem domains:
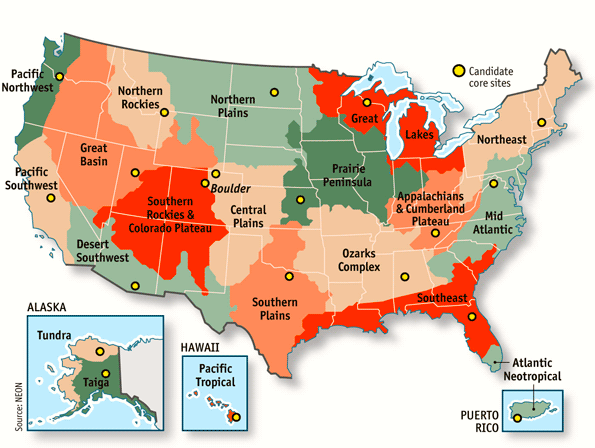
This is a categorization of places or locations, along with labels for each category. And of course it pays no heed to state boundaries.
There are a great many ways of dividing the U.S. into regions, each way having its own purpose or function.
Here’s a (relatively gross) categorization by physical features, which will of course bear a relationship to the categorization by ecosystems:

The simplest categorization of regions I’m familiar with is the one I was taught in grade school (and is apparently still taught). This one collects states into five big categories:

(Sometimes the southwest and southeast are combined to make the South.) Students are encouraged to find commonalities within each region and differences between the regions. The system is easy to teach (and test); it fits fairly well with folk ideas about regional differences (having to do with sociocultural distinctions — in food, other customs, speech, etc.); and it also aligns closely with the categorization used by the Census Bureau..
I turn now to this case, and to other regional categorizations set by federal law or regulation. The U.S. Census Bureau uses four big regions (Northeast, Midwest, South, and West), with nine divisions (New England, Mid-Atlantic; East North Central, West North Central; South Atlantic, East South Central, West South Central; Mountain, Pacific). Statistics are reported by state, by division, and by region.
Similar to this categorization, but different from it in a number of details, is the system of ten standard Federal Regions established by the Office of Management and Budget for federal agencies.
Then there are the twelve Federal Reserve districts and the thirteen Courts of Appeals circuits (twelve based on region, plus the Federal Circuit).
These categorizations respect state lines. So, for the most part (but with some striking divergences), do the divisions into seven time zones (from Hawaii-Aleutian to Atlantic), distinguished roughly by longitude.
Leaving now categorizations set by law or regulation, I return to am important set of socioculturally defined regional distinctions, namely dialect areas. Here we’re faced with the enormous complexity of the data: different linguistic features tend to run together, but only approximately, and sometimes they cross-cut one another, so the categorization of dialects can be done at many different grains, from coarse (with only a few big dialect areas) to very fine (with a great many). (In addition, many significant dialect distinctions are not primarily regional: racial and ethnic dialects, class dialects, urban vs. rural dialects, etc.)
Faced with this profusion, the editors of the Dictionary of American Regional English fixed on a complex set of regional labels:
An unusual feature of DARE is its inclusion of maps showing where words were found during the nationwide fieldwork. The maps are adjusted to reflect population density [state by state] rather than geographic area, so they look a bit strange at first, but one learns to “read” them quickly. Whenever possible, the editors apply regional labels to the entries, based both on the maps from the field survey and on the written citations. (There are nearly forty regional labels listed in the front matter to Volume I, but the most frequently used in the text of the Dictionary tend to be for the “South,” “South Midland,” “North,” “New England,” “Northeast,” “West,” “Gulf States,” and “southern Appalachians.”)
These labels are further qualified by reference to age, race, level of education, rural vs. urban location, and finer-grained geographical specification (down to reference to specific cities).
At one grain, you get very large dialect areas, like Southern — indicated approximately on this map, based on multiple dialect studies:

More refined classifications divide this area into several large subareas, plus smaller dialect islands (like New Orleans and the Georgia/South Carolina “low country”).
In many cases, lexical features, syntactic features, and phonological features don’t align closely, so that different dialect classifications result, depending on which features are used. Hans Kurath in 1949, using lexical features, defined a large Midland area, later divided into North Midland and South Midland (with the South Midland treated by still later scholars as part of the South — the Upper South), and then on the basis of phonological criteria an Inland North area was carved out of this territory:
The Inland North dialect of American English is spoken in a region that includes most of the cities along the Erie Canal and on the U.S. side of Great Lakes region, reaching approximately from Herkimer, New York to Green Bay, Wisconsin, as well as a corridor extending down across central Illinois from Chicago to St. Louis.
This dialect used to be the Standard Midwestern speech that is traditionally regarded as the basis for General American in the mid-20th century, though it has been since modified by an innovative vowel shift known as the Northern Cities Shift, which has altered its character.
… The dialect was used for comedic effect in the Saturday Night Live skit “Bill Swerski’s Superfans” [fans of the Chicago Bears], and in the film The Blues Brothers.
More specifically:
The Inland North consists of western and central New York State (Syracuse, Rochester, Buffalo, Binghamton, Jamestown, Olean); northern Ohio (Akron, Cleveland, Toledo); Michigan’s Lower Peninsula (Detroit, Flint, Grand Rapids, Lansing); northern Indiana (Gary, South Bend); northern Illinois (Chicago, Rockford); and southeastern Wisconsin (Kenosha, Racine, Milwaukee). This is the dialect spoken in America’s chief industrial region, an area sometimes known as the Rust Belt.
Note that Pittsburgh and Erie PA (and Youngstown OH) are excluded from the area.
(You probably never thought of this area as a “region” of the U.S. It takes linguists to dream up things like that.)
The cities in the area (but not necessarily the surrounding countryside) participate in a complex set of vowel shifts:
The Northern cities vowel shift [NCVS] is a chain shift in the sounds of some vowels in the dialect region of American English known as the Inland North.
The area in question:
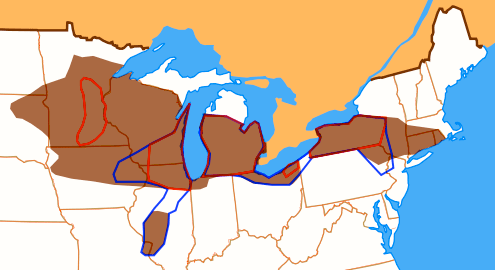
Three isoglosses identifying the NCVS. In the brown areas /ʌ/ is more retracted than /ɑ/. The blue line encloses areas in which /ɛ/ is backed. The red line encloses areas in which /æ/ is diphthongized to [eə] even before oral consonants. The areas enclosed by all three lines may be considered the “core” of the NCVS; it is most consistently present in Syracuse, Rochester, Buffalo, Detroit, and Chicago.
[From: Labov, William, Sharon Ash, and Charles Boberg (2006), The Atlas of North American English (Berlin: Mouton de Gruyter), p. 204]
There are six sound changes involved here, given numbers by Labov et al. (indicating the order in time in which the changes appeared), along with a code word serving as a pointer to the set of words undergoing the change; four of the changes are very clearly in a chain.
1 is raising and tensing of /æ/ (TRAP) (see above) [prominent in the Swerski sketches, in words like basketball]
6 is lowering and backing of /ɪ/, approximating [ɛ] but not merging with /ɛ/ (KIT)
Then the chain ɛ → ʌ → ɔ → ɑ → a (where the arrows indicate approximation of one vowel to another):
4 is backing and lowering of /ɛ/ towards [ʌ] (DRESS) (see above)
5 is backing of /ʌ/ towards [ɔ] (STRUT) (see above)
3 is lowering of /ɔ/ to [ɑ] (THOUGHT)
2 is fronting of /ɑ/ to central [a], or even front [æ] (COT) (prominent in the Swerski sketches, in words like Bob and Todd]
(Of course, there’s considerable variation from speaker to speaker, and within the productions of a single speaker, and the changes have progressed to different degrees in different places.)
If you don’t have the NCVS in your own speech, you’ll probably find words taken out of context very hard to identify, since you’ll hear the tokens (especially those illustrating the more recent changes) as belonging to your own vowel system; you’ll hear intended mess as muss, intended dug as dog, intended bit as bet. Labov regularly amazes audiences with recordings in which individual words have been snipped out of their context.
September 2, 2012 at 10:56 am |
I find it very weird when “the South” includes Arizona and New Mexico. Perhaps those get shifted from “Southwest” to “West”?
September 3, 2012 at 3:22 pm |
A different take on the problem is The Nine Nations of North America. I remember reading it in 1981 or so, when it came out, and thinking this might be a very good way to split things up.